好!我中了! 速记 11-667实验
你中了甚么!


终于在token和模型大小的限制下通过了perplexity的要求,
题目要求75以下可以拿一半分,50以下可以拿满,对于我这种对模型一窍不通的人肯定要把调参的分拿到(bushi)
整个调参还是比较累的,一开始需要找到模型优化方向,大概花了半天时间把指标压到了100以下,这个时候其实只是基本排除了一些关系不大的参数,没有什么理解。
然后100进75可以说没怎么费力就运气好通过了。
75进50是最为痛苦的, 尤其是有一次

这种情况谁吃得消啊()
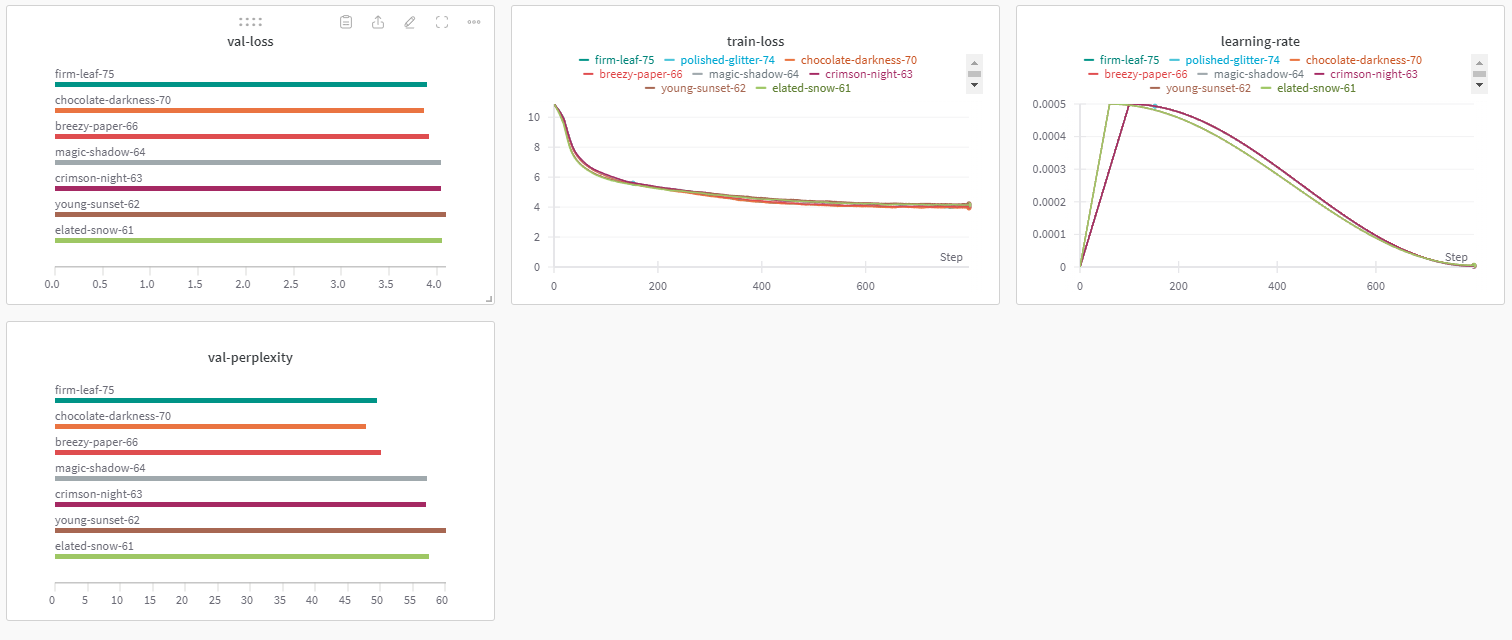
又经过了十多轮的调整参数,因为在实验过程中可以发现 embeding的维度是非常影响最后成绩的,但是这个参数也会极大影响最后模型大小,导致你没办法调整太大的参数(第70轮我只是稍微超出了模型大小限制一些就很容易通过测试了)
后来发现层数本身也会提升模型的性能,一开始担心模型参数量不大,深层次的内容并不会学到太多,但实际情况是,提升模型层数可以在不显著增加模型大小的情况下有着可观提升。
最后降低了模型的head 数量,一开始会想到,更多的注意力头会学到更多的内容,后来觉得由于embeding层并不大,再划分太大的head导致每个head分到的内容都很少基本学不到什么规律,降低了head以后终于通过了50大关。
(本次实验都基于autodl的4090,总开销大约在20RMB,羡慕正式register的有aws的credit可以用)
最后的最后,附上通关测试,关于这部分会有另外的博客,虽然是经典transformer,但是从如此底层不借助科技手段完成依旧能学习很多,敬请期待。